Over the christmas holiday I had an idea and developed the foundation for a small application which involves RDF, a SPARQL endpoint and a bunch of ordinary web pages available in a number of languages. Each page is a representation of a paper document that exists in the real world.
Each real document has been assigned a URI like http://example.com/act/31977D001. Thus it represents a non-information resource. What should happen if you enter that URI in a web browser? Well, the server shouldn’t return a HTTP 200 status code. That would imply that the resource is an information resource.
So, my idea is currently to try this:
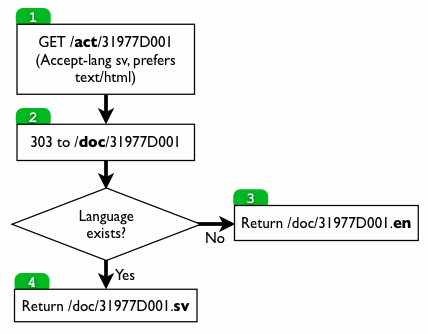
I am not sure about it yet, but this is the first try.