The training of Large Language Models and their subsequent use in AI chatbots require access to vast amounts of data, often scraped from various online sources, including news websites. This data is crucial for the bots to understand and generate human-like text.
However, this practice of data scraping seems to have raised concerns among news websites. AI systems like ChatGPT can be seen as potential competitors in the news business. When chatbots are asked about current events, they can generate answers that rely on data from news websites. While it fuels the advancement of AI, it also poses potential issues such as copyright infringement and loss of ad revenue.
How did news websites and media companies respond?
Method
To get an understanding of the evolution of AI bot blocking on news websites I have collected the robots.txt file for the top 50 news websites from January 2023 until April 2024. The files were collected from the excellent Internet Archive Wayback machine from the first day of every month. This resulted in 800 robots.txt files that were checked for AI user agent settings.
Looking at recent examples of robots.txt files I collected a list of potential user agent strings for AI-related crawlers.
While some are used directly from chat bots in a dialogue the Common Crawl dataset plays a pivotal role in the training of LLMs. It is a publicly available web archive that contains petabytes of data from billions of web pages. The Common Crawl user agent was also added to the list of user agents to check.
The following user agents were used:
| User agent | Description |
|---|---|
| anthropic-ai | Anthropic, makers of Claude. |
| CCBot | Common Crawl scraper. |
| ChatGPT-User | OpenAI’s bot used by plugins in ChatGPT. |
| cohere-ai | Cohere. |
| FacebookBot | Facebook’s crawler for public web pages to improve language models. |
| Google-Extended | Google’s bot to improve Gemini Apps and Vertex AI generative APIs. |
| GPTBot | OpenAI’s web crawler. |
| PerplexityBot | Perplexity Lab’s crawler. |
The check the downloaded robots.txt files, a Python script using the urllib.robotparser module was used. If the user agent was blocked for the path “/” it was added to the data. Google News blocks all user agents for “/” and was removed from the dataset.
Results
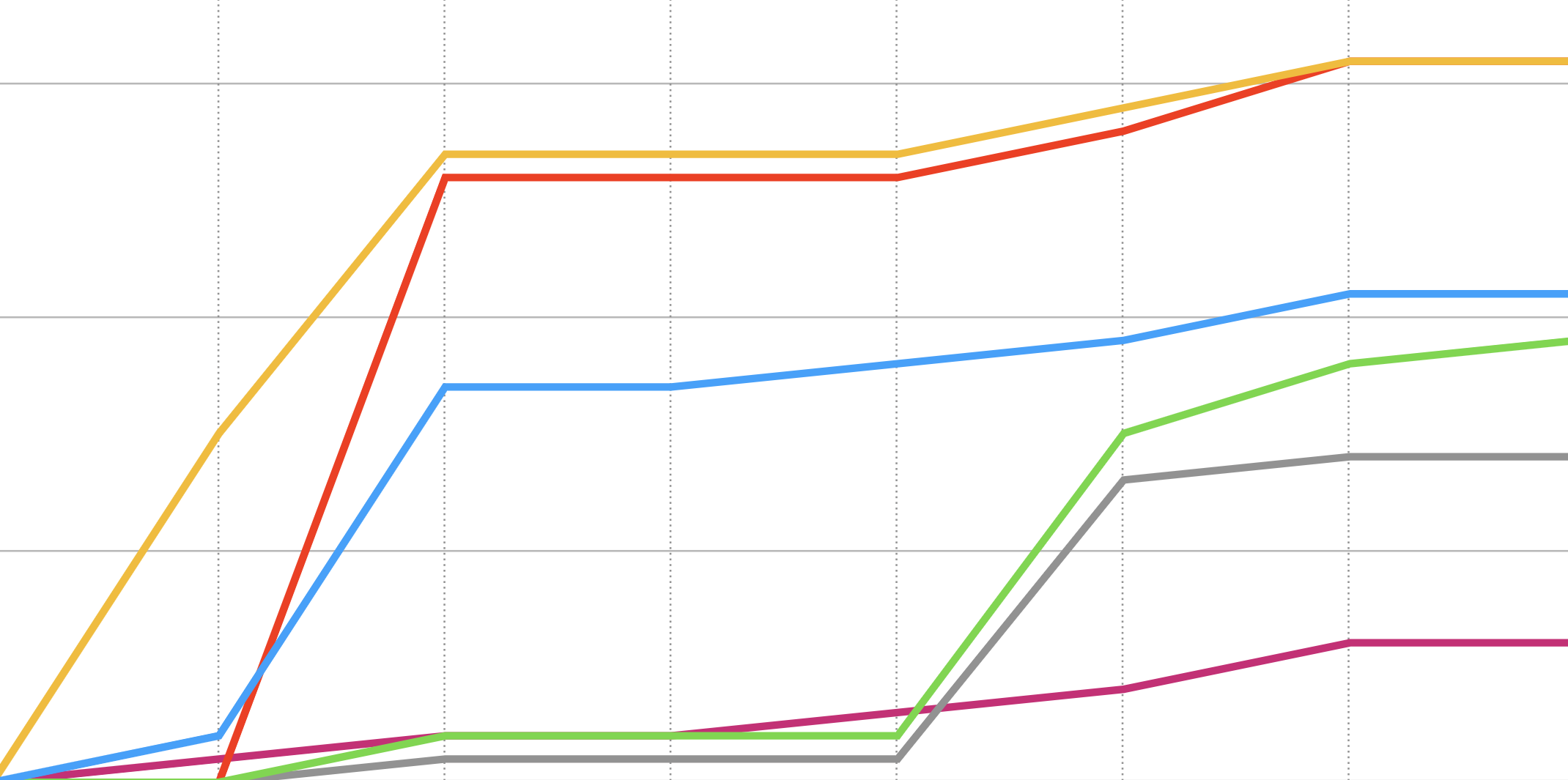
Before September 2023 there were no website blocking the user agents apart from a few blocking the Common Crawl bot. But starting in September/October of 2023 many news websites added the OpenAI GPTBot to their blocking strategy.
Number of blocked AI bots by the top 50 US news sites by month
Data source: Internet archive robots.txt files. Press Gazette Top 50 news websites in the US (March 2024)

Comparing the top 50 US websites with a similar list of Swedish news websites the result looks similar. Many started blocking AI bots in late 2023. I have not found an explanation to why the transition happened at that time. OpenAI launched ChatGPT Enterprise in late August 2023 but the lawsuit by the New York Times were not filed until December that year.
Number of blocked AI bots by the top 50 Swedish news sites by month
Data source: Internet archive robots.txt files. Orvesto Internet (top 50 news sites)

Swedish publishers see to prioritize blocking the Google-Extended user agent over smaller companies like Anthropic. Maybe that will impact the competition?
Implications
What happens if LLMs get limited access to quality web data and instead rely on fringe websites or pure disinformation websites? This is a potential problem for users of LLMs in the future.
What will happen to online journalism if LLM Chat bots lets users query the web for answers without having to visit the source website? How will ad revenue be impacted?
Will smaller less known AI startups have an advantage as they are less frequently blocked compared to established AI companies?
References
- Training Data for the Price of a Sandwich, Mozilla Foundation, 2024.
- Will Perplexity Beat Google or Destroy the Web?, Hard Fork Podcast, New York Times, 2024.
- The Times Sues OpenAI and Microsoft Over A.I. Use of Copyrighted Work, New York Times, 2023.
- Top 50 news websites in the US (March 2024), Press Gazette, March 2024.
- Orvesto Internet, Kantar/Orvesto, March 2024.